
헬로티 이동재 기자 | KAIST 전산학부 이재길 교수 연구팀이 적은 양의 훈련 데이터가 존재할 때도 높은 예측 정확도를 달성할 수 있는 새로운 딥러닝 모델 훈련 기술을 개발했다고 27일 밝혔다. 기술이 적용되면 기존에 수작업으로 진행돼 많은 노동력과 시간이 소모되던 레이블링(Labeling) 과정을 보다 효과적으로 수행할 수 있다. 이번에 개발된 기술은 심층 학습 모델의 훈련에서 바람직하지 않은 특성을 억제해 충분하지 않은 훈련 데이터를 가지고도 높은 예측 정확도를 달성할 수 있게 해주는 기술이다. 연구팀은 바람직하지 않은 특성을 억제하기 위해서 분포 외(out of distribution) 데이터를 활용했다. 다량의 분포 외 데이터를 추가로 활용해 추출된 특성이 영(0) 벡터가 되도록 심층 학습 모델의 훈련 과정을 규제해, 바람직하지 않은 특성의 효과를 억제하는 원리다. 기존에 딥러닝 과정에서 분포 외 데이터는 쓸모없는 것이라 여겨지고 있었으나, 이번 연구에선 오히려 훈련 데이터 부족을 해소할 수 있는 유용한 보완재로 탈바꿈됐다. 연구팀은 이 정규화 방법론을 ‘비선호 특성 억제’라고 이름 붙이고 이미지 데이터 분석의 세 가지 주요 문제에 적용했다. 그 결
[첨단 헬로티] ▲ ETRI 임준호 선임연구원이 코버트(KorBERT) 작동 원리를 설명하고 있다. 과학기술정보통신부와 정보통신기획평가원(IITP)의 혁신 성장동력 프로젝트로 추진 중인 엑소브레인 사업에서 최첨단 한국어 언어모델을 공개했다. 이로써 인공지능(AI) 비서, AI 질의응답, 지능형 검색 등 한국어를 활용한 인공지능 서비스 개발이 한층 고도화될 것으로 전망된다. 한국전자통신연구원(ETRI)은 10일, 최첨단 한국어 언어모델 ‘코버트(KorBERT)’를 홈페이지를 통해 공개했다. 연구진이 공개한 모델은 두 종류다. 구글의 언어표현 방법을 기반으로 더 많은 한국어 데이터를 넣어 만든 언어모델과 한국어의 ‘교착어’ 특성까지 반영해 만든 언어모델이다. 특히, 이 기술은 올해 3월, 한컴오피스 지식검색 베타버전에 탑재됐으며 하반기에는 ETRI의 언어모델을 활용한 ‘법령 분야 질의응답 API’를 추가 공개하고 ‘유사 특허 지능형 분석 기술’도 출시를 목표하고 있다고 전했다. 언어처리를 위한 딥러닝 기술을 개발하기 위해서는 텍스트에 기술된 어절을 숫자로 표현해야 한다. 이를
상호명(명칭) : ㈜첨단 | 등록번호 : 서울,아54000 | 등록일자 : 2021년 11월 1일 | 제호 : 오토메이션월드 | 발행인 : 이종춘 | 편집인 : 임근난 |
본점 : 서울시 마포구 양화로 127, 3층, 지점 : 경기도 파주시 심학산로 10, 3층 | 발행일자 : 2021년 00월00일 | 청소년보호책임자 : 김유활 | 대표이사 : 이준원 |
사업자등록번호 : 118-81-03520 | 전화 : 02-3142-4151 | 팩스 : 02-338-3453 | 통신판매번호 : 제 2013-서울마포-1032호
copyright(c)오토메이션월드 all right reserved
UPDATE: 2026년 02월 13일 11시 42분























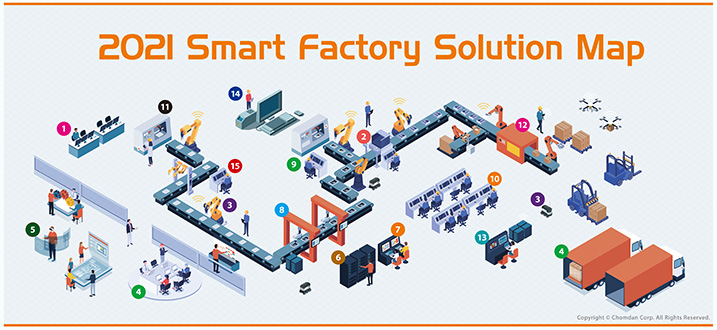


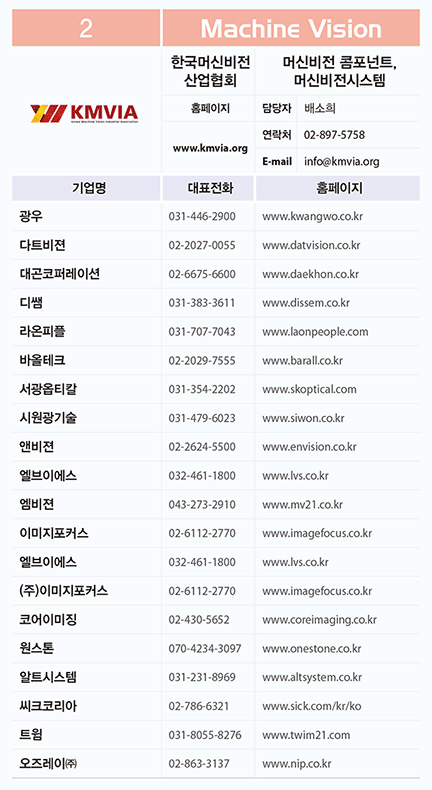

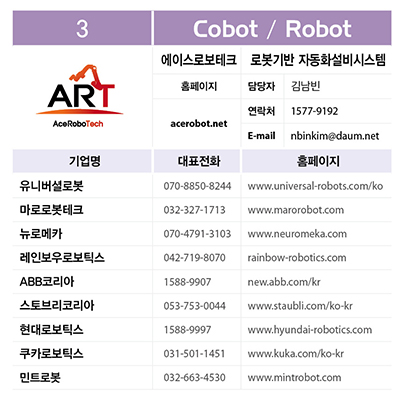

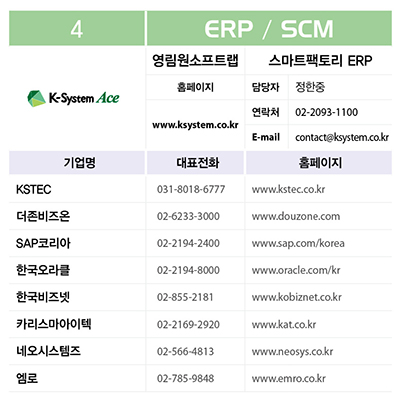

























/pdf.png)
/smartmap_2_01.png)
/smartmap_2_04.png)
/smartmap_2_big_04.jpg)
/smartmap_2_05.png)
/smartmap_2_big_05.jpg)
/smartmap_2_08.png)
/smartmap_2_big_09.jpg)
/smartmap_2_09_2.png)
/smartmap_2_big_10_2.jpg)

/smartmap_2_11_2.png)
/smartmap_2_big_12_2.jpg)
/smartmap_2_02.png)
/smartmap_2_03.png)
/smartmap_2_06.png)
/smartmap_2_big_07.jpg)
/smartmap_2_07.png)
/smartmap_2_big_08.jpg)
/smartmap_2_12.png)
/smartmap_2_big_13.jpg)
/smartmap_2_13.png)
/smartmap_2_big_14.jpg)
/smartmap_2_14.png)
/smartmap_2_big_15.jpg)
/smartmap_2_15.png)
/smartmap_2_big_16.jpg)
/smartmap_2_16.png)
/smartmap_2_big_17.jpg)
/smartmap_2_17_2.png)
/smartmap_2_big_18_2.jpg)
/smartmap_2_18_2.png)
/smartmap_2_big_19_2.jpg)
/smartmap_2_19._2.png)
/smartmap_2_big_20_2.jpg)
/smartmap_2_20.png)
/smartmap_2_big_21.jpg)
/smartmap_2_21.png)
/smartmap_2_22.png)
/smartmap_2_23.png)
/smartmap_2_24.png)
/smartmap_2_25.png)
/smartmap_2_26.png)
/smartmap_2_27.jpg)