[헬로티]
고객들은 생산 과정에서 발생하는 대용량 데이터를 실시간 수집, 저장, 조회, 그리고 분석을 위한 빠른 데이터 추출을 요구한다. 마크베이스는 시계열 전용 데이터베이스 솔루션을 활용함으로써 고객의 데이터 처리 한계를 극복하고 스마트 팩토리를 고도화했다. 지난 9월에 개최된 ‘제4회 스마트 제조 베스트 프랙티스 컨퍼런스’에서 마크베이스 김성진 대표가 강연한 스마트 팩토리 고도화 전략에 필요한 데이터 처리 한계 극복 방안에 대한 내용을 정리했다.
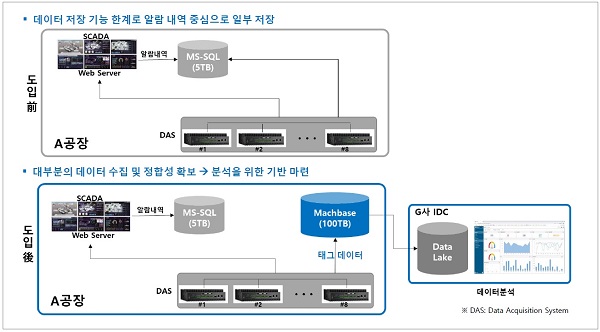
그림 1. 데이터 처리 시스템 구성도
그동안 수많은 스마트 팩토리가 구축되었고 지금도 구축 중이다. 스마트 팩토리를 제대로 활용하기 위해서는 생산 과정에서 발생하는 데이터를 잘 수집하고 저장하고 실시간 조회가 가능해야 한다. 그러나 현실은 어려운 문제가 많다. 왜냐하면 데이터가 너무 많을뿐더러 모두 관리하기도 어렵기 때문이다. 마크베이스의 고객 중 하나인 음료공장 사례를 통해 고객 요구사항을 어떻게 해결하고 데이터 처리 한계를 극복해서 스마트 팩토리를 고도화했는지에 대해 소개하겠다.
고객 요구사항
고객의 니즈를 3가지로 요약하면 이하와 같다. 첫 번째는 모든 태그 데이터를 저장하고 싶다. 센서가 1,000개가 됐든 10,000개가 됐든 대규모 데이터를 실시간으로 수집하고 저장하길 원했다. 둘째는 이렇게 저장된 대용량 데이터는 빠른 백업이나 히스트리 형태로 보관되어 데이터 조회가 편했으면 한다. 셋째는 대규모 데이터를 빨리 추출하여 데이터 분석을 하고 싶다.
이 3가지 요구사항이 완벽하게 갖춰진다면 좋을 텐데, 현실적으로는 어렵다. 그 이유는 고객의 페인 포인트(Pain Points)를 보면 알 수 있다.
첫째, MS-SQL 저장 성능의 문제이다. 마이크로소프트의 MS-SQL은 많이 사용되고 있지만, 센서에서 나오는 데이터를 대량으로 저장하는 것은 다른 차원의 문제이다. 즉, 거래정보를 초당 수백에서 수천 건 정도를 처리하는 게 목적이지 수많은 센서에서 발생하는 데이터를 한꺼번에 저장하기 위해서 만들어진 게 아니다. 그럼에도 많은 개발자들은 워낙 저변이 넓기 때문에 이 데이터베이스를 사용하고 있다.
둘째, MS-SQL에 대용량 데이터를 모두 저장할 수 없다 보니 일부 데이터만 MS-SQL에 저장하고, 나머지 대량의 데이터는 CSV 파일로 보관한다. 이렇게 해서 한 달이 지나고 수개월이 지나면 저장된 CSV 파일은 수 GB에서 수십 TB 정도가 된다. 그렇게 되면 데이터 확인과 추출이 거의 불가능해진다.
셋째, 기존 DBMS(데이터베이스 관리시스템)에서의 대량 레코드 입력 시 DBMS의 주기적인 장애가 발생한다.
넷째, 일 300GB의 데이터가 발생하게 되면 디스크 공간부족 현상이 일어나 압축이 필요하며, 저장 공간의 부족으로 인한 주기적 테이블 백업이 필요하다.
이처럼 몇 가지의 고객 페인 포인트(Pain Points)를 보면 빅데이터 문제가 여전히 상존하고 있음을 알 수 있고 더구나 스마트 팩토리가 IoT 영역으로 오면서 심각하게 이런 문제들이 발생하고 있다.
그러면 실제 공장에서의 데이터 구성과 형태는 어떠해야 하는지 살펴보겠다. 마크베이스가 진행한 D음료를 생산하는 A공장 내 적용사례이다. 이 공장은 모든 데이터를 저장하기 위해서 초당 10만 건 이상의 데이터를 수집해야 했으며, 이렇게 모은 데이터양은 하루에 336GB, 1년이면 123TB가 생성된다. 고객은 이 데이터를 모아서 활용하겠다고 결정했기 때문에 나중에 지우더라도 우선 모으는 것이 이 프로젝트의 목적이었다.
그래서 구성을 DAS(Data Acquisition System) 8대와 데이터베이스 관리시스템으로 Machbase Fog Edition 6.1을 사용했으며, 모아진 데이터는 DAS에서 CSV 단위로 저장했다. 이렇게 해서 추정되는 데이터 용량은 15만 개 태그에서 초당 1건 씩 저장하게 되어 하루에 336GB가 모일 것으로 예상된다. 여기에 제공된 하드웨어는 단일 서버인 윈도10 환경에 인텔 Xeon(3.2G)과 메모리(RAM 16G×8), 저장장치(SSD : 실시간 서비스용 400GB×2, HDD:백업용 1.92TB×5) 형태로 구성됐다.
태그 종류는 품질 관련 데이터 1,000개와 설비 데이터 150,000개로, 고객은 여기서 수집된 모든 데이터들을 저장하고 싶어 했다.
마크베이스를 적용하기 전과 후의 시스템 구성도를 비교해 봤다. 사례로 든 D음료의 A공장은 일반 공장에 비해 데이터양이 상당히 많았다. 적용 전의 이 공장은 데이터 저장 기능 한계로 일부 주요한 데이터를 웹서버를 통해 SCADA 시스템으로 보내서 모니터링을 하고 알람 정보만 MS-SQL에 입력했다. 그리고 나머지 저장 못한 데이터는 DAS 8대에 CSV 단위로 저장할 수밖에 없었다.
그러나 마크베이스의 데이터 처리 방식을 시스템에 적용함으로써 대부분의 데이터 수집과 정합성이 확보되었고 분석을 위한 기반도 마련됐다. 사실, 알람 내용은 많아 봤자 수십 만 건에 불과하기 때문에 MS-SQL에 원래 목적대로 알람 내역만 저장하여 관리하도록 하고 실제 저장하기를 원하는 태그 데이터의 경우 시계열 데이터베이스에 모두 저장하는 형태의 시스템을 구성했다. 그리고 데이터 분석을 위해서는 다양한 조건의 데이터를 빠르게 가져와야 분석이 신속하게 이루어질 수 있기 때문에 데이터 레이크(Data Lake) 시스템을 마크베이스에 연동을 제안했다.
도입 효과
작업 공정은 3단계로 진행했다. 1단계는 실제 데이터 입력 방법 및 성능 검증이다. 이를 위해 센서(태그)는 19만 개, DAS는 8대를 설치하여, 초당 발생하는 데이터 건수는 19만 건, 일별 건수는 164억 건이나 되었다. 입력 방법은 C#을 통한 마크베이스 Append API를 활용했다.
2단계는 데이터 백업 및 확인 프로세스 검증이다. 이를 위해 태그 테이블 및 로그 테이블에 대해서 증분 백업 기능을 제공하기로 했다. 증분 백업은 데이터베이스의 전체 백업 이후, 변경되거나 추가된 데이터만 선택적으로 백업하는 방식으로, 전체(full) 백업에 비해 데이터양이 적고 소요시간이 짧다는 장점이 있다. 리스토어 조회에 있어서도 필요할 때 백업된 데이터를 마운트 기능을 사용하여 특정 시점의 데이터 조회가 가능하도록 했다. 그 결과 리스토어 과정 없이 백업 파일에 대한 초 단위 마운트 및 검색이 가능해졌다.
3단계는 데이터 분석 프로세스 검증이다. JDBC(Java DataBase Connectivity)를 통해서 태그명, 날짜 조건을 기준으로 필요한 데이터를 수집하여, 현업 데이터 레이크팀에서 각종 불량요인 분석과 추적할 수 있도록 했다.
지금까지 살펴본 고객 요구사항에 대한 해결 방안을 정리하면 △데이터의 고속 입력을 위해서는 Append 함수를 통해 고속으로 입력할 수 있었고 △빠른 백업은 태그 테이블 증분 백업으로 해결했으며, △백업된 데이터의 빠른 확인은 마운트 기능을 활용함으로써 백업 파일에 대한 즉시 복원 및 검색/추출이 가능해졌다. 그리고 △고속 입력 시 원시 통계데이터 검색 성능을 위해서는 Rollup Table을 활용한 단/장기 통계 데이터를 활용했고 △저장 공간의 효율적인 사용을 위해서는 태그 테이블의 논리적, 물리적 압축 기능을 활용함으로써 원시 데이터 대비 40~50% 이상 압축할 수 있었다.
그 결과 고객은 기존 데이터베이스를 사용했을 때보다 시계열 전용 데이터베이스 솔루션을 활용함으로써 더욱 빠르고 안정적인 데이터 수집이 가능해졌다. 또한, 실시간 압축을 해주기 때문에 예전보다 훨씬 적은 저장소로도 많은 데이터를 저장할 수 있었다. 그리고 태그 테이블 증분 백업 기능으로 데이터를 언제든지 실시간으로 볼 수 있게 됐다. 그 외 데이터를 Append로 대량 입력하는 중에도 백업이나 삭제가 가능하고 백업된 파일을 마운트 기능을 통해 유용하게 활용 수 있었다.




