[첨단 헬로티]
필자는 전산공무원으로 사회생활을 시작하였고, 그 후 왕컴퓨터코리아에서 메인프레임 시스템의 시스템 엔지니어로서 은행의 메인프레임및 Swift시스템을 기술지원하다가 미ㅈ국 본사의Eastman KODAK으로 사업부가 합병되어 EDS코리아의 컨설턴트로 옮겨 컨설팅 업무를 하였다. 이후 NCR테라데이타로 옮겨 DW에 첫발을들여놓게 되었고 계속 정보계 관련 업무를 진행해 왔다. 또 서강대학교 대학원 IT경제학를 졸업한 그는 2004년도에 대한민국정부에서 신지식인으로 선정되었고 국가경쟁력 강화라는 서훈이유로 행정자치부장관 표창을 받았다. 그리고 가입 기업 수가 약 6,000여 개인중국시장을 공략하려는 사람들의 모임 대표를 맡고 있고 한국데이터인큐베이터 CTO,숭실대학교 정보과학대학원 겸임교수로 재직 중이며, 다수의 빅데이터 서적을 저술했다.
세계적인 기업들은 데이터를 중심으로 한 혁신적인 서비스 및 제품을 창출하는 역량의 확보에 기사활을 걸고 있다. 더욱이 새로운 기술, 블록체인, 핀테크, 클라우드, 사물 인터넷 등 다양한 기술 확보를 통한 혁신적 서비스에 접목하기 위한 다양한 시도를 하고 있다.찰스 다윈은 인간은 그 어떤 동물보다 오래 살아남을 수 있는 비결은 변화에 적응하는 능력이라고 하였다. 비즈니스에서도 성장의 원천은 다양한 힘의 논리와 균형 속에서 변화에 적응하는 능력이라고 생각한다. 이러한 능력을 데이터의 확보에서 찾을 수 있고 이러한 변화에 능동적으로 대응하는 능력을 통찰력이라고 정의하고 이러한 통찰력은 좀더 많은 데이터에 기인하고 있다는 것은 새삼 새로운 것이 아니다. 비즈니스가 더욱 고도가 되어 가면서 빅데이터의 중요성이 더욱 커지고 있다.
1. 데이터에 대한 고찰
빅데이터를 통하여 데이터는 인포메이션으로 가공되고 인포메이션은 지식과 지혜로 발전하게 되게 된다. 종래의 DIKW이론이 인공 지능 시대에도 그대로 적용이 되고 있는 것이다.
빅데이터와 인공 지능을 통해서 우리의 패러다임이 변화되고 있는 것이다.
[그림1]과 같은 빅데이터와 분석을 기반한 인공 지능으로의 진화에서와 같이 우리의 해당 비지니스에 대해서 늘 물음과 선택을 통해서 발전시켜 나가고 있다.
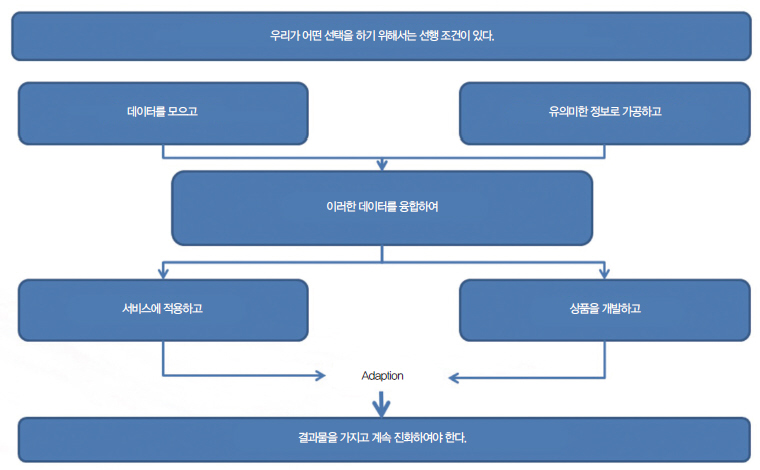
▲ 그림1. 빅데이터와 분석을 기반한 인공 지능으로의 진화
이러한 문제를 해결하기 위해서 끝없이 데이터를 모으고 분석하고 학습하여 딥러닝, 인공 지능으로 다가갈 것이다.
첫째, 우리는 어떠한 데이터를 가지고 있고 활용이 가능한가?
둘째, 우리에게 유용한 데이터는 어떤 것이 존재하는가?
셋째, 고객 행동에 기반한 근본 원인에 기인한 데이터는 어떤 것이 있는가?
넷째, 예측 과정에 따른 결과에 어떤 행동이 이루어지고 있는가? 등 다양한 데이터의 이해가 준비되어야 한다.
이렇게 준비된 데이터를 통해서 우리는 데이터에 대한 인식을 통해서 다양한 학습을 통한 예측 모델을 끊임없이 만들어 가는 것이고 이를 통해서 끝없이 선택하는 것이 인공 지능인 것이다.
데이터에 “도구를 이용하고 수학적, 통계학적 접근 방법을 사용하여 실제적인 비즈니스의 해답(예측)을 도출하는 일련의 활동”이 빅데이터 기반의 분석인 것이다.
예를 들어,
(1) 어떤 행위를 하면 우리의 건강에 도움이 될까?
(2) 어떤 금융 상품이 우리에게 도움을 줄까?
(3) 어떤 선택에 대한 결과에 대한 측정은 무엇으로 하는가?
(4) 10년후 우리 회사는 어떤 회사로 성장할 수 있는가?
(5) 경제와 부동산은 어떤 관계가 있고 어떻게 비즈니스에 접목이 가능한가?
(6) 효과적인 기계 장비는 어떻게 운영하여야 비용을 아끼며 효율적인 운영이 가능한가? 등 도메인에 대한 끊임없는 전략이 위와 같은 물음에서 출발하여야 할 것이다.
위와 같은 데이터와 물음에 대한 효율적인 대안으로 빅데이터 시스템을 고려하고 있고 이러한 빅데이터시스템은 어떻게 구축하여 하는가? 하는 당면 과제에 직면할 것이다.
2. 성공적인 빅데이터 구축을 위한 요소
성공적인 빅데이터 시스템을 구축하기 위한 4가지 요소가 존재한다.
(1) 프로세스 진단을 통한 데이터 진단 : 과거, 현재에 대한 기업 내부의 수준 파악을 통해서 데이터의 가치를 보는 기업 내의 성숙도를 진단한다. 이 부분에는 기존 업무 및 데이터에 대한 진단이 선행되어야 한다. 이러한 부분은 향후 구축하게 될 빅데이터 프로젝트의 성공을 가능하게 하는 중요한 요소이다.
(2) 데이터 기반의 빅데이터 전략 : 빅데이터의 전략 계획을 수립하여야 한다. 해당 기업의 미션과 비전에 기반한 경영학적인 전략을 모색하여 한다. 이러한 부분이 선행되지 못하면 어떤 목표가 없는 데이터 만들어지므로 결과가 의미 없어지기도 한다
(3) 지식의 내재화 : 각 업무 부서의 협업으로 만들어진 데이터 관련 경험을 지식(Knowledge)를 내재화를 통해 고도화를 해 나가야 한다. 이러한 기반에서 딥러닝, 인공 지능으로 발전해 나가는 기반이 되는 것이다.
(4) 분석에 대한 고도화 : 빅데이터에 대한 분석적 사고의 내재화가 필요하다. 데이터를 이해하고 이를 통한 업무 도메인에 접목하여 분석을 고도화하는 데이터 사이언티스트의 육성을 해야 할 것이다.
이러한 성공적인 빅데이터 구축의 4가지 요소를 준비한 후, 빅데이터와 인공 지능을 통해서 비즈니스와 서비스를 어떤 관점으로 진행 할 것인지 보아야 할 것이다.
(1) 신상품 개발에 활용할 것인지?
(2) 프로세스 개선을 통해서 업무를 효율적으로 개선할 것인지?
(3) 비용을 절감하는 요소로 활용할 것인지?
(4) 영업 활동 및 서비스의 개선으로 활용할 것인지? 에 대한 빅데이터 관점을 정립해야 할 것이다.
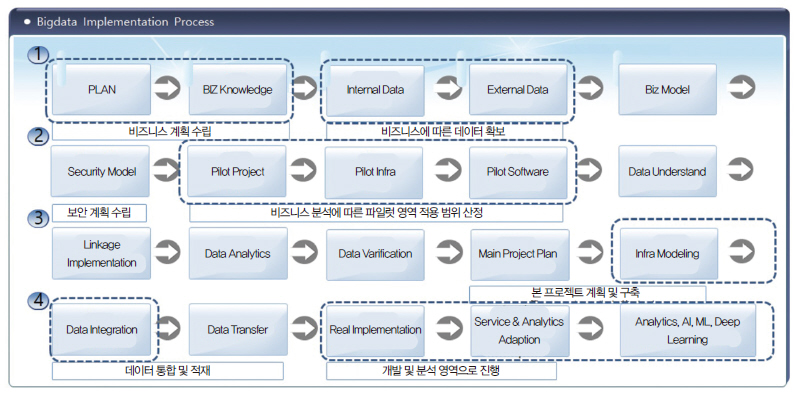
▲ 그림2. 빅 데이터 구현 프로세스
3. 인공 지능으로 가기 위한 빅데이터 프레임 워크
3.1. 빅데이터에 대한 이해
첫째, Connection : 데이터와 데이터에 대한 연결에 대한 이해가 필요하다. 이러한 연결선은 기업과 기업, 기업과 상품, 상품과 상품, 상품과 서비스등 다양한 연결선의 분석을 통해 네트워크의 형성을 이해하는데 도움이 된다.
둘째, Centrality : 많은 데이터에서 중심에 대한 분석으로 데이터 중의 허브를 중심으로 만들어 지는 데이터 네트워크에 대한 분석이다.
셋째, Cohesion : 데이터의 Cluster가 만들어 졌으면 이러한 데이터 사이에 응집력 등에 분석이 필요하다. 이러한 응집력은 데이터간에 형성된 군집에 밀도를 나타낸 것이다.
넷째, Equivalence : 데이터 간에 해당하는 역할들을 나타낸 것이다. 이것을 통하면 전혀 의미가 없는 데이터 사이에서도 어떤 역할, 등가 등을 찾을 수 있다. 특히, 데이터 융합에서 매우 유용하게 활용이 가능하다.
이러한 네 가지의 데이터에 대한 이해를 통하여 성공적인 빅데이터가 가능한 프레임 워크 설계가 가능해 진다.
3.2. 빅데이터 구현 시 프로세스 절차
다음은 빅데이터 구현 시 프로세스에 대한 절차를 나타낸 것이다.
각각의 구현 프로세스는 각각 4단계로 영역별로 구분되어 있다.
1번 단계는 주로 빅데이터 전략에 관련된 부분으로 데이터 거버넌스를 포함하고 있다. 그리고 2번 단계에서는 실제 구현하기 전 단계의 파일럿 단계로 보안에 관련된 부분과 데이터의 법적인 부분까지 포함이 되며 3단계에서는 실제 데이터를 연계하고 분석하는 영역이다. 그리고 4단계에서는 데이터를 통합하고 향후 ML, DL, AI등 다양한 데이터의 사용에 기인하는 부분이라고 할 수 있다.
각각의 절차에는 다음과 같은 기술적 요소가 요구되며 관련 기술은 다음과 같이 정의할 수 있다. 이러한 부분은 빅데이터 처리시 수집, 저장, 처리, 분석을 통한 일련의 프로세스에 관련 요소들이 접목되어 효율적인 빅데이터 시스템 고유의 처리가 이루어진다.
[표1]에 구분된 영역에 따라 다양한 기술 요소가 포함되어 있어 많은 경험과 학습을 통해서 이루어져야 한다. 이렇게 구축된 빅데이터는 다양한 데이터와 융합되어 효율적인 결과를 도출할 수 있게 된다.
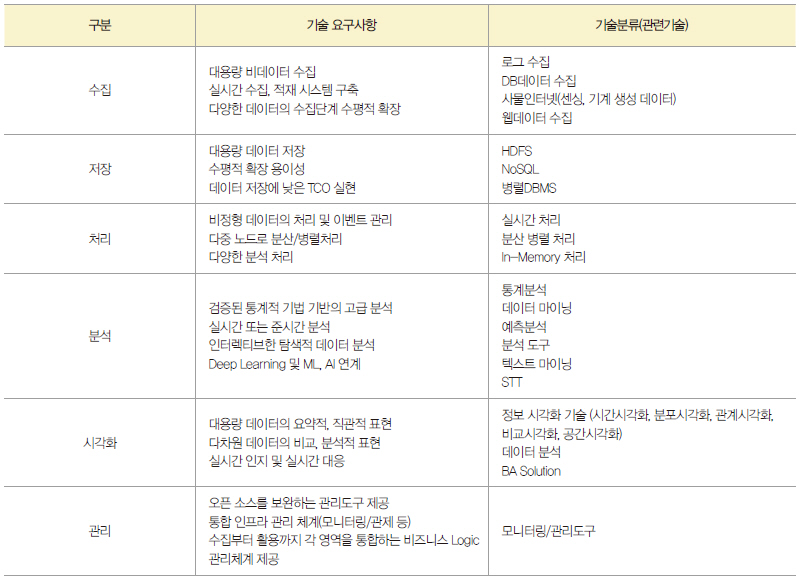
▲ 표. 빅데이터 시스템의 기술 요소 분류 및 관련 기술
각각의 기술요소에는 오픈 소스 기반의 기술요소가 중심이 되며 다양한 ECO 소프트웨어가 목적별로 소프트웨어 생태계를 이루고 있다.
예를 들어서 데이터의 수집에는 정형데이터베이스에서 데이터를 추출하는 Sqoop(SQL To Hadoop), 비정형데이터에서 데이터를 추출하는 Flume등이 있으며 실시간 데이터를 처리할 때 메시징 큐 역할을 수행하는 Kafka등 다양한 에코 소프트웨어 존재하며 데이터와 서비스의 형태에 맞는 효율적인 소프트웨어를 적용하여야 한다.
[그림3]은 빅데이터 기반의 인공 지능 처리 단계를 표시한 것으로 각각의 단계는 인공 지능에 활용되는 음성 인식, 이미지 처리, 비정형 텍스트 기반 처리 등 다양한 비정형 데이터의 처리에 관련 관련 부분을 설명한 것이다.
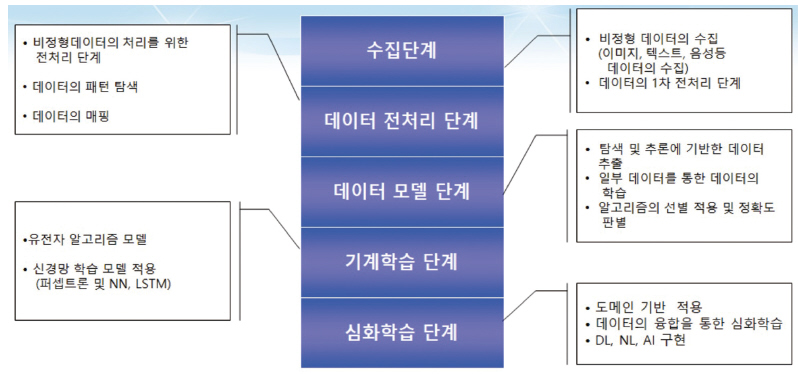
▲ 그림3. 빅 데이터 기반의 인공 지능 처리 단계
데이터 모델 단계에서부터 인공 신경망(ANN:Artificial Neural Network)등 다양한 모델에 적용되어 인공 지능 등으로 발전하고 있다. 이러한 인공 지능에 중심이 되는 신경망은 지도 학습, 비지도 학습, 강화 학습 등 다양한 모델을 포함하고 있으며 기존에 생성된 데이터를 통한 Input, Output, Hidden등으로 되어 구현이 가능하다. 이러한 것을 가능하게 하는 라이브러리, 알고리즘 등을 계속적으로 발전되어 있고 자율 주행 자동차, 음성 인식 등에 적용이 되어 구현 되고 있는 것이다.
이러한 빅데이터 기반의 인공 지능은 헬스케어, 금융, 제조, 보험, 유통등 전 산업군에서 다양한 영역에 활용, 적용되고 있다. 이를 효과적으로 구현 가능하기 위해서는 데이터를 모으고 이를 가공해서 효과적인 학습이 이루어지는 데이터의 선순환이 이루어져야 인공지능으로 가능 길이 훨씬 수월하지 않을까 생각한다.
데이터인큐베이터코리아 문영상 CTO




